
Temporal degradation framework and other ideas
Update on writing my Master's thesis in public. Excuses, sketches and first results.

It’s been a while since the last post. But I have some good excuses, or at least that’s what I tell myself.
Part of building in public is communicating with the same transparency when things are going on track as when they are getting messier. So, as part of my “Building my Master’s thesis in public“ effort, let me start with why it’s been so long since the last update.
Why I haven’t sent an update
The last couple of months have been pretty busy. I went from working part-time at NannyML to working full-time. I wrote four new blog posts. One of them got Hacker-News viral, and another was the most upvoted post in the r/MachineLearning subreddit of the day. (yeih!)

Plus, together with my colleague Maciej, we reviewed every single word of the NannyML docs and gave it a new glow. And now, if you now look at the source code, you’ll see that most of the functions are typed and better documented! We also built a chat-gpt bot that explains the complexities of the EU AI Act to people interested in learning about it, but that doesn’t want to go through all 107 pages of the regulation.
So yeah, it has been some fun and busy weeks. Where sadly, I left this newsletter a bit behind…
New progress
But ok, not all are excuses. I do have some progress to show!
You may not remember what my thesis is about, so here is the short pitch.
Last year a paper published in Nature magazine called Temporal quality degradation in AI models showed how ML models' performance can degrade over time. In the analysis, the authors ran multiple experiments and found that 91% of their models suffered from model degradation.
To identify temporal model performance degradation, they designed a testing framework that emulates a typical production ML model. And ran more than 20,000 dataset-model experiments following that framework.
I plan to replicate this testing framework, check if I can find similar results with other datasets, and go a step further by measuring how many of the degradation issues would have been alarmed/avoided by performance estimation methods (CBPE, DLE) provided in the NannyML library.
On that note, I have already implemented the first version of the model evaluation framework. It looks something like this.
Temporal model degradation framework
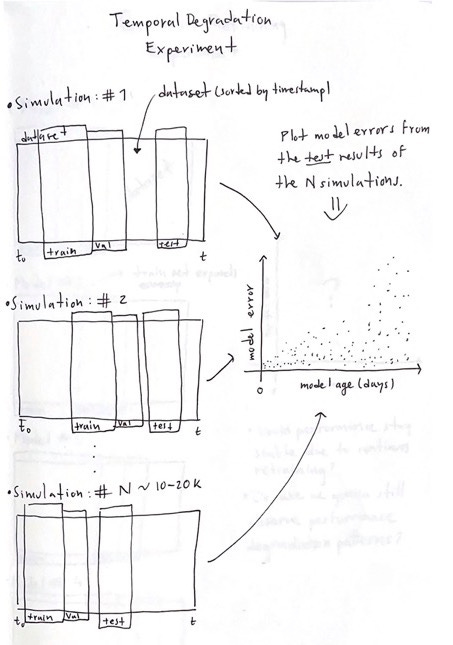
To begin, we have a dataset arranged in chronological order based on when each observation was gathered. Next, we sample three smaller subsets from this original dataset.
The first subset will be the train set, and its initial timestamp is randomly selected from the original dataset.
The second one is adjacent to the train set and will be the validation set.
Finally, the third one is randomly selected from any point in the future and will serve as the test set.
After sampling these three subsets, we train an ML model and collect the training, validation, and test scores. Once we have done that, we repeat the process 10-20k times. So, in the end, we’ll have the results of 10-20k ML models, each trained with a different subset and tested on a random point in the future. This will allow us to plot a model aging chart.
In the sketch, I drew one representing an expected result. A model whose performance degrades as time passes. I hope the image is clear enough to understand the idea of the experiment. (I haven’t shown it to anyone, so, leave me a comment if you have any questions).
I already implemented this experiment and ran 1000 simulations using the California House Pricing dataset. Here is an early result.
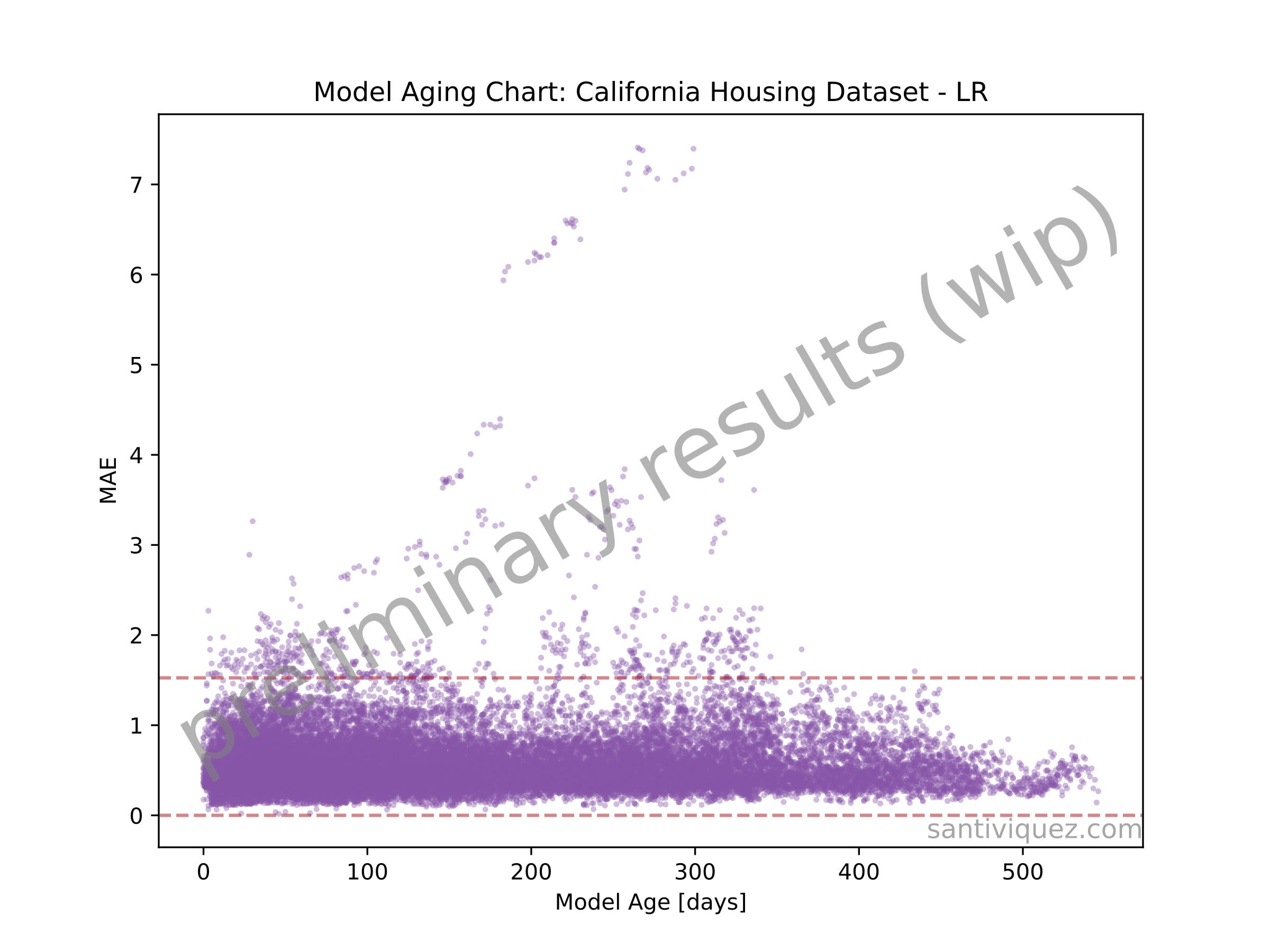
The above plot shows the evolution of the model’s performance. The x-axis, called Model Age, represents the number of days that have passed since the model was last validated.
Each purple point represents the MAE obtained on a specific day after the model was released. The red dashed lines are the lower and upper thresholds. Currently, the upper threshold is set at three standard deviations from the mean of the MAE obtained from the validation set. And everything that is above that threshold is considered a performance degradation.
From the 1000 models built in this particular experiment, 940 generalized well enough on the validation set. And from those 940 models, 920 degraded at least once. These are very early results, but so far, they support what the paper Temporal quality degradation in AI models showed.
Continuous Retraining Experiment
I’ve also been doodling another experiment that I’m curious to try. Most companies tackle the performance degradation problem by doing continuous retraining of their ML models.
Every once in a while, after they have collected more data, they increase their training set and re-fit the model with the purpose of building a more robust model that hopefully does not degrade in the near future.
With the continuous retraining experiment, I want to test that hypothesis and see if the degradations we observed in the previous simulations disappear by continuously retraining the ML models. The experiment goes like this.
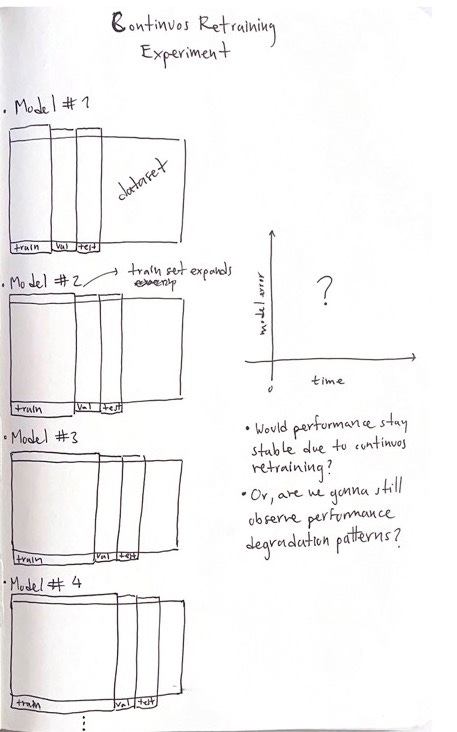
Again, we start with a dataset and select the first N_train_0 observations to build a train set. The following N_val adjacent observations are gonna be the validation set. Similarly, the following N_test adjacent observations to the validation set will be the examples used as a test set.
The idea is to build a model with this configuration and collect the test scores. In the second iteration, we expand the training set by setting N_train_1 = N_train_0 + N_val. And the validation and test sets are gonna be shifted accordantly.
With this, after each iteration, the train set grows, allowing the model to capture more distributions and making as able to test the hypothesis that continuous retraining fixes the performance degradation problem.
In the end, we plot the model’s performance evolution. Right now, I see two possible outcomes:
The performance stays stable thanks to continuous retraining.
Or, we still observe degradation patterns.
I haven't finished setting up this experiment, so I'll share the results in the next update. :)
What’s next?
Welp, I still need to formalize the Temporal Model Degradation Framework because there are some things that I would like to investigate further. Such as:
What is the best way to programmatically identify good models? Right now, I’m considering a model is good if its validation score is below three standard deviations from the mean of the training score.
What is the best way to set up thresholds for identifying a model whose performance has degraded? Right now, I’m considering as a degradation everything that is bigger than three standard deviations from the mean of the validation score.
I will also implement the Continuous Retraining Experiment and test these simulations with the other datasets and model types.
To finalize, if you have read till here, I really appreciate you ❤️. Let me know if you have any suggestions. I’m very excited to discuss more about these experiments.
I’m constantly writing about data science and machine learning on Twitter and LinkedIn. Follow me if you want to check what I share there :)