
Continuous retraining and formalizing the model aging framework
Update on writing my Master's thesis in public. Formalizing the results of the temporal degradation framework and first results on the impact on model performance when doing continuous retraining.

Two weeks ago, in the previous email, I presented two of the frameworks I'm implementing in my thesis for measuring how the performance of ML model changes over time—specifically, the temporal model degradation framework and the continuous retraining one.
On it, I left some open questions, which I planned to answer in this email, and promised to share some updates on the first results of the continuous retraining experiment. Let's start with some of the improvements I've made to the temporal degradation experiment.
Temporal degradation improvements
Last time I shared this sketch to explain the temporal degradation experiment. Now, the logic remains the same, except for a little detail.
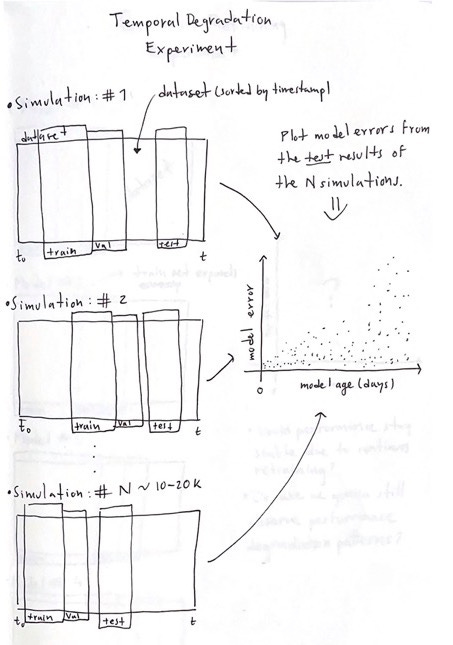
Before, I did a simple train-val split in each simulation to train and validate each model. Now, I'm doing cross-validation in a TimeSeriesSplit manner. Doing this will allow me to do a better job when tuning the model's hyperparameters.
The other big difference in the framework is how I decide whether a model is good enough to evaluate it in production.

In the last email, one of my unresolved questions was: What is the best way to programmatically identify good models? At the time, I considered that a model was good if its validation score was below three standard deviations from the mean of the training score.
But after some experiments, I found that rule to not be consistent enough when aggregating data in different periods. So, now I'm using the test set to validate if a model is good enough by checking if the model's error on the test set is smaller than an arbitrary number. (e.g., Test MAPE < 20%). This way, verifying that we only study the performance degradation of good models is easier. Checking if a model is good is fundamental since studying the degradation of models with a poor initial fit is not worth it and can bias the results.
Here is an early result of 100 simulations of the temporal degradation experiment using the California housing dataset with a LightGBM model.

We can see how initially, the model starts with a low-performance error, and before the first 100 days of production, its performance starts to deteriorate. All the models from this simulation had a Test MAPE < 20%, so it is interesting to see many of them reaching MAPE values bigger than 40%.
For the next updates, I will share similar studies using different datasets and models.
Continuous retraining results
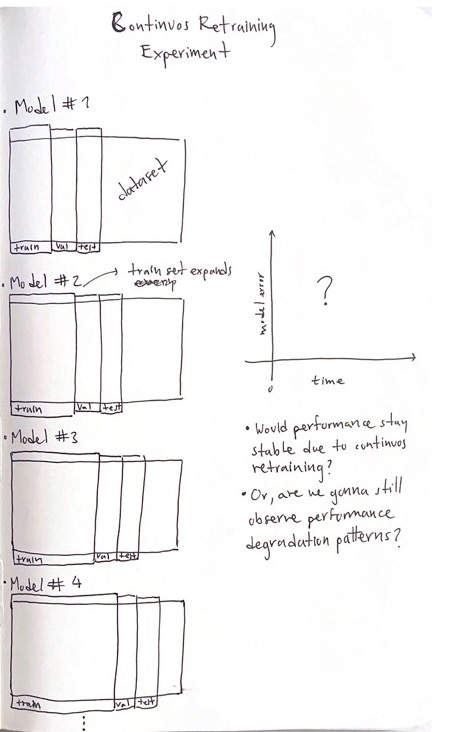
Last time I only shared the sketch of the continuous retraining experiment. This time I'll show an early and interesting result.
To combat the performance degradation issue, companies tend to re-fit/update their models occasionally with new data to build a more robust model that hopefully does not degrade in the near future. The continuous retraining experiment aims to check if these updates can decrease the number of performance degradations.
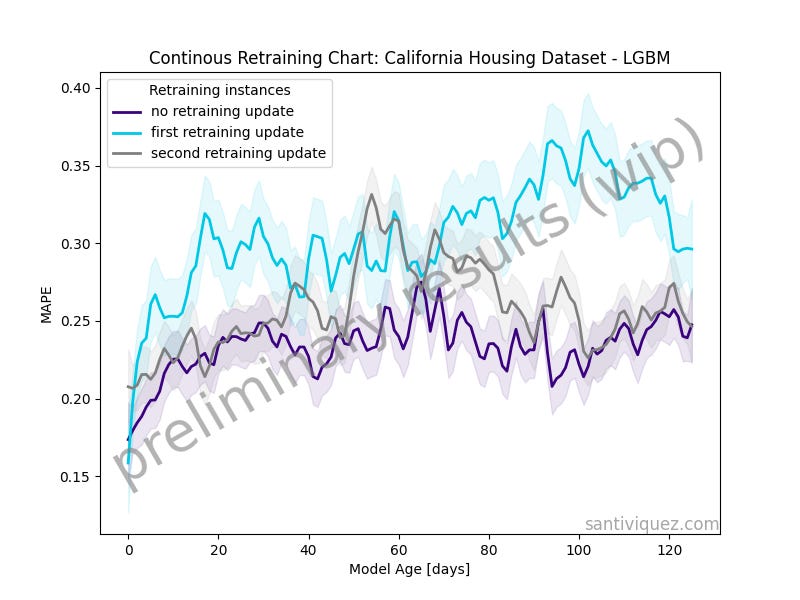
The above plot was produced after running 10 model simulations where each independent model was updated every 3 months.
The purple line represents the performance trend of the model before any retraining update. You can think about it as the performance trend of the first 3 months of the model in production.
The light-blue line is the performance trend after the first update. To update the model, I kept the initial training set and added the previous 3 months of production data.
Similarly, the grey line is the performance trend after the second model update.
It is interesting to see how, in this specific case, the model performs the best before any update is implemented. I still need to try this with different datasets and models, but this is a nice first result.
What's next?
There is a lot of stuff still to do, but the good news is that the two main frameworks are almost done. After they are complete, I can start running formal experiments on different datasets and algorithms.
For the next update, I plan to:
Implement auto hyper-parameter tuning in both the temporal degradation and the continuous retraining frameworks.
Design a framework to check how many degradations would have been estimated by NannyML.
And before I plug my Twitter and LinkedIn, I want to thank everyone who reads till this line! Sharing these updates with the world is a huge motivation to keep working on this problem during the week.
I’m constantly writing about data science and machine learning on Twitter and LinkedIn. Follow me if you want to check what I share there :)